BACKGROUND
What was the objective?
Despite the broad design of after-school programs to accommodate all students, there is an opportunity to personalise the experience and address the unique needs of individual students.
This approach aims to proactively identify and target students based on their talents, performance, abilities and socio-economic status, with the goal of improving outcomes and enhancing program effectiveness. However, the current lack of personalised targeting and proactive intervention hinders the potential for maximising the impact of after-school programs on student development and success.
This UX case study was part of a final-year undergraduate project. The objective of this research was to experiment with synthetic/artificial data as a solution to the small dataset problem.
the challenge
Small datasets and the big problems they cause
With limited data, learning algorithms reach their accuracy limits. To overcome this, organisations and individuals either obtain more data or shift focus to descriptive and diagnostic analytics before moving to predictive analytics.
It’s essential to consider the impact of small data on prediction models. Small data poses challenges due to information gaps, making models unreliable and undependable.
The small dataset problem can affect many industries and sectors, including education. I’m passionate about addressing this issue in education, focusing on school programs. Schools offer various programs, from sports to extracurricular clubs and after-school classes. However, determining what is most beneficial and who should participate is a question.
USER RESEARCH
School programs and student outcomes
Currently, educational interventions often rely on previous exam scores and, in rare cases, socio-economic status. They are also less predictive and more prescriptive, thus missing the opportunity to be proactive.
What if teachers and student counsellors had more information about their students before the school year began? With this information, they could design programs tailored to benefit smaller groups of students.
In an effort to ascertain feasibility and understand current user behaviour the following was revealed:
- Schools are increasingly using technology to manage various aspects of education
- The National Education Management Information System (NEMIS) is a mandatory requirement for all public schools in Kenya, following government policy
- The Digi-School programme, launched in May 2016, has successfully distributed a total of 1,068,250 laptops to 19,666 schools, meeting the minimum requirements for the application.
- Implementing the system has led to an overall improvement in exam performance
- School officials have been able to create programs that enhance students’ performance through the generation of relevant models.
Sneak peek into the experiment
Using this open dataset from two Portuguese public schools, I began to train a model to simulate a real-world school with real students. The dataset contained information about the students, ranging from family composition to absent days and even what their parents do for a living.
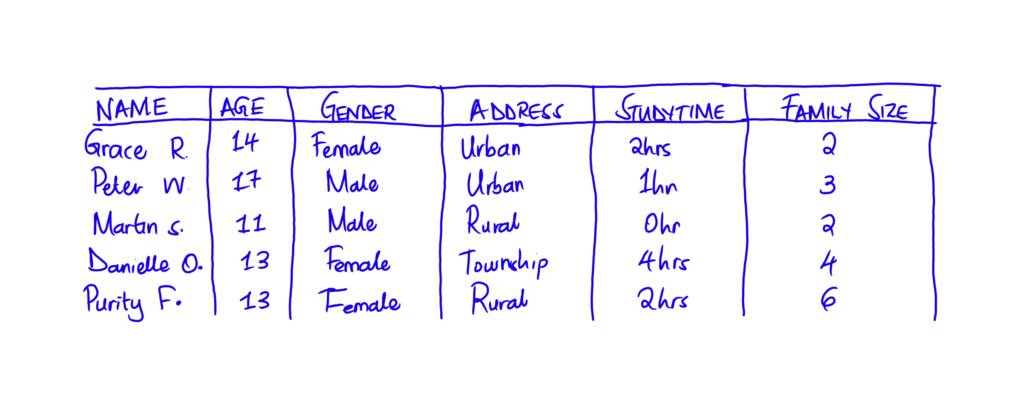
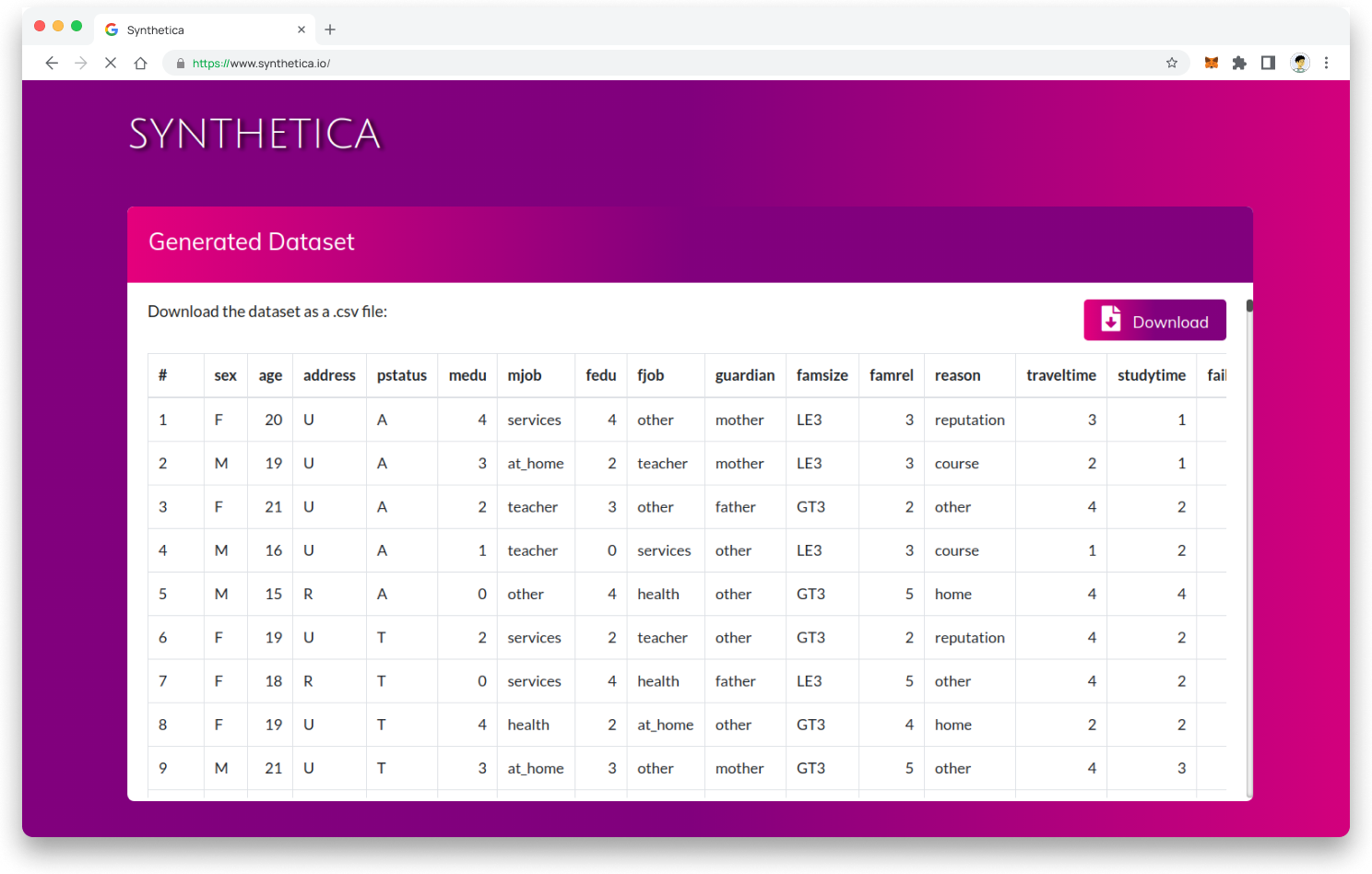
I generated synthetic data for the experiment based on the dataset below with similar characteristics and variables. Afterwards, I evaluated the efficiency of the artificial data by evaluating it based on the following criteria:
- Data Quality: How well does the synthetic data match the quality and distribution of real-world data?
- Model Performance: Does the synthetic data lead to comparable or improved model performance compared to real-world data?
- Computational Efficiency: Is the synthetic data computationally efficient to generate and process?
- Privacy and Security: Does the synthetic data maintain privacy and security standards?
personas
User personas


ideation
User flow
The proposed solution would help teachers and school counsellors:
- Automate the creation of artificial data using their own generated and essential variables
- Involve simple and straight-forward flow from data proposal to data acquisition
- To simulate a variety of scenarios and student outcomes to ensure as many outcomes as possible are accounted for
- Result in downloaded data that can be used for further analysis using more user-accessible software like Microsoft Excel and/or complex tools like Python programming language
features
Automating artificial data generation
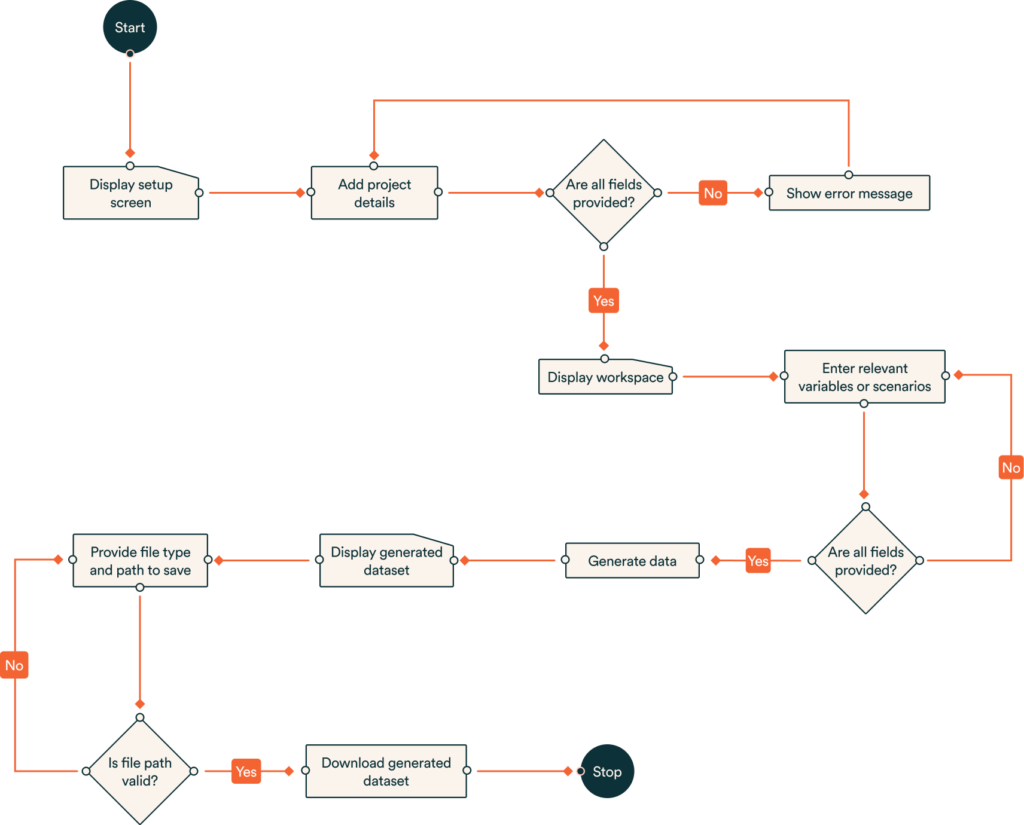
The UI was organised as a step-by-step process to simplify a complicated process while easing the cognitive load. Filling out all required fields, except for human error, ensured that the user generated correct data.
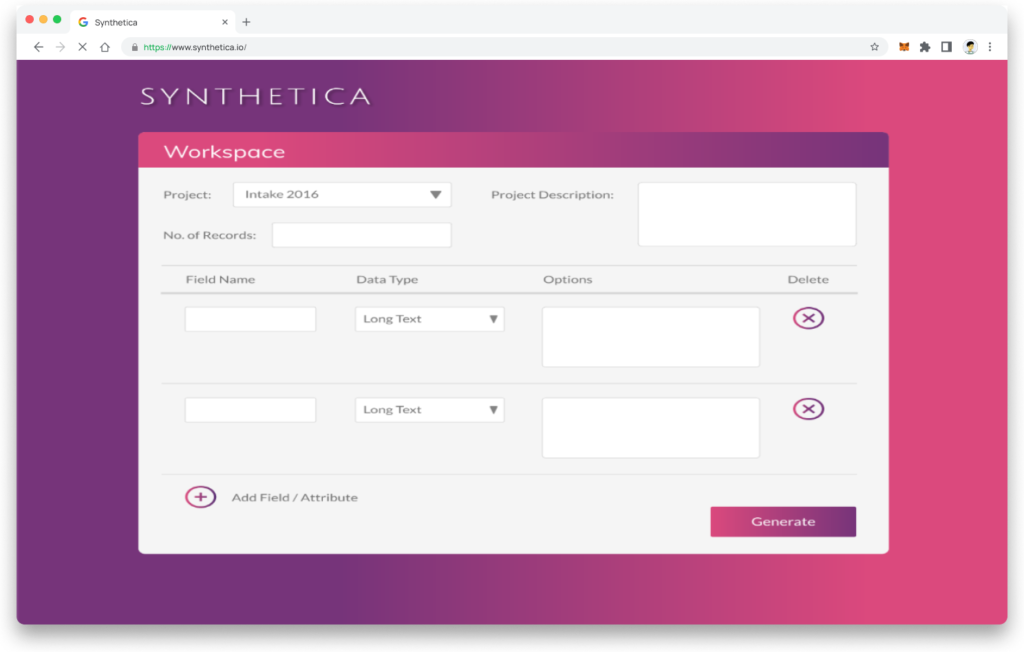
Required data or scenario specifications:
- Project: select a school intake that is related to the data you want to generate
- Project description: (not required) brief description of the project
- No. of records: the number of rows needed for the dataset. This field could correspond to the number of students in a class, intake or the entire school.
- Field name: the variable(s) you want to generate data for, i.e. family_relation, parents_job, distance_school
- Data type: is the field going to have text, numeric or boolean data
- Options: the library (Trumania) should generate artificial data within defined bounds. For example, distance_school, the ranges could be 1 to 20km.
- An option to delete a field that is not required
- An option to add a field
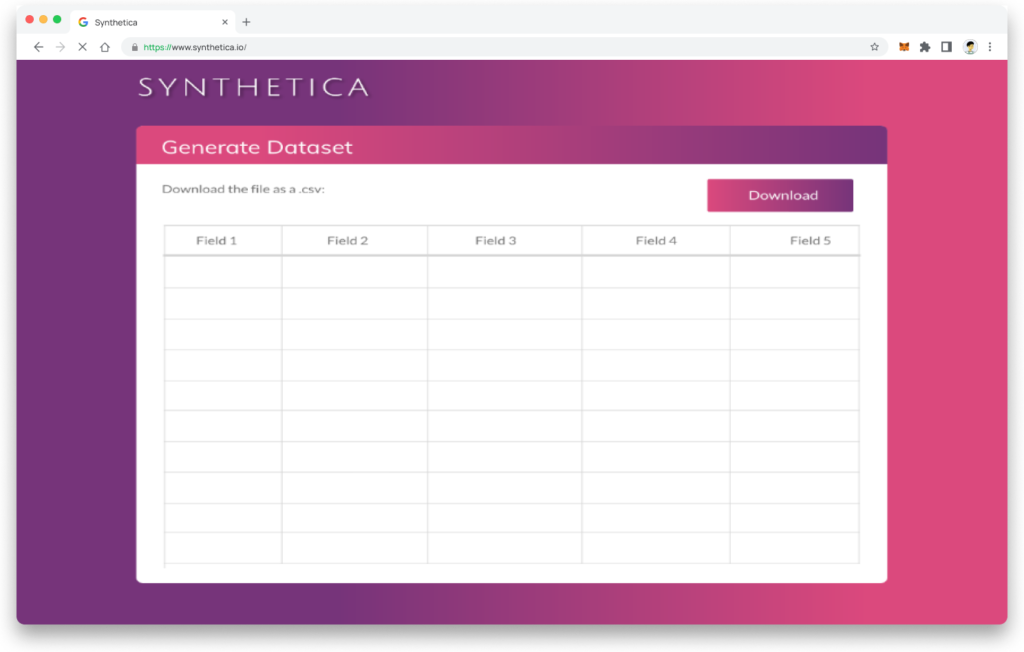
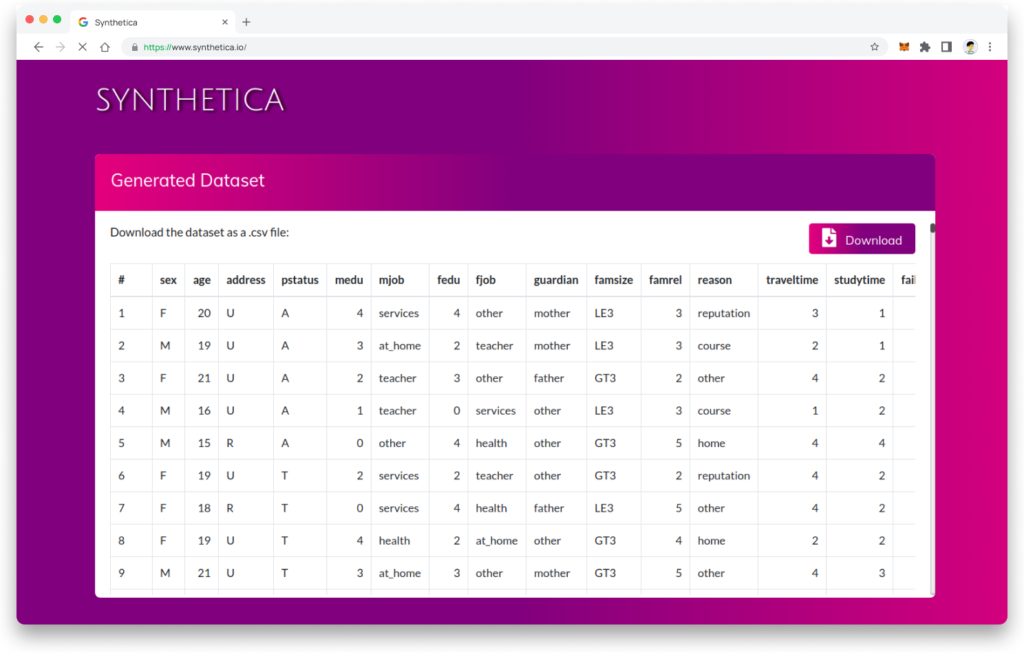
- Clicking ‘Generate’ reveals an artificial dataset based on the user’s specifications on a modal.
- The user can scroll the window to view the data-table.
- ‘Download’ allows the user to retrieve a copy of the data for analysis as either .csv or .xlsx
in hindsight
A reflection on lessons learnt
Artificial data is becoming increasingly important for commercial applications in machine vision and large language model annotations. Today, synthetic data is being used to address more than just data scarcity.
Reflecting on this, I have learned the following:
- Using synthetic data makes more sense for higher-ranking education officials aiming to improve student outcomes.
- The primary target audience would be data analysts in the education sector.
- Although the target audience has changed from teachers and school counsellors, they still have a role in helping fine-tune the data to represent the situation on the ground. As such, the tool could be leveraged to encourage such collaboration across the board.
- Improving the usability by working with full text rather than camel case is essential.
- While exploring the role of synthetic data generation in this experiment, it would have been valuable to demonstrate how education officials and staff could utilize this data.
- Segmenting the data generation process into focused (goal) modules would enhance the user experience.